
智能科学与工程学院胡涛教授团队一项成果被CCF-A类国际会议ACM MM'24录用
发布时间:2024-07-22 点击量: 来源:智能科学与工程学院 作者:
 打印
打印 第三十二届国际多媒体会议(ACM International Conference on Multimedia, ACM MM)将于2024年10月28日-11月1日在澳大利亚墨尔本召开。智能科学与工程学院胡涛教授团队的一篇长文被录用,论文题目为“Audio Deepfake Detection with Self-Supervised XLS-R and SLS Classifier”,胡涛教授为论文通信作者,第一作者为2022级信息安全专业硕士生张齐山,第二作者为2023级应用数学专业硕士生文双兵,湖北民族大学为唯一单位。ACM MM是国际多媒体领域最重要的顶级会议,被中国计算机学会CCF推荐为A类的国际学术会议,是多媒体领域国际首屈一指的盛会,旨在展示多媒体领域的科学成就和创新工业产品。本次会议共收到4385篇有效投稿,最终录用1149篇,录用率为26.20%。
生成式人工智能技术,包括文本到语音(TTS)和语音转换(VC),经常与真实样本无法区分,这给个人区分真实和合成内容带来了挑战。这种不可区分性破坏了人们对媒体的信任,任意克隆个人语音信号对隐私和安全构成了重大挑战。在Deepfake音频检测领域,目前实现更高检测精度的大多数模型都采用自监督预训练模型。然而,随着Deepfake音频生成算法的不断发展,保持对新算法的高分辨精度变得越来越具有挑战性。为了提高Deepfake音频特征的灵敏度,项目组提出了一种包含SLS(敏感层选择)模块的Deepfake语音检测模型。具体来说,利用预训练的XLS-R使本模型能够从其各个层中提取不同的音频特征,每个层都提供不同的判别信息。利用SLS分类器,提出的模型能够捕获不同层次音频特征的敏感上下文信息,并有效地将这些信息用于伪音频检测。实验结果表明,本方法在ASVspoof 2021 DF和In the Wild数据集上都达到了最先进的(SOTA)性能,在ASVspoof 2021 DF数据集上的等错率(EER)为1.92%,在In the Wilds数据集上为7.46%。
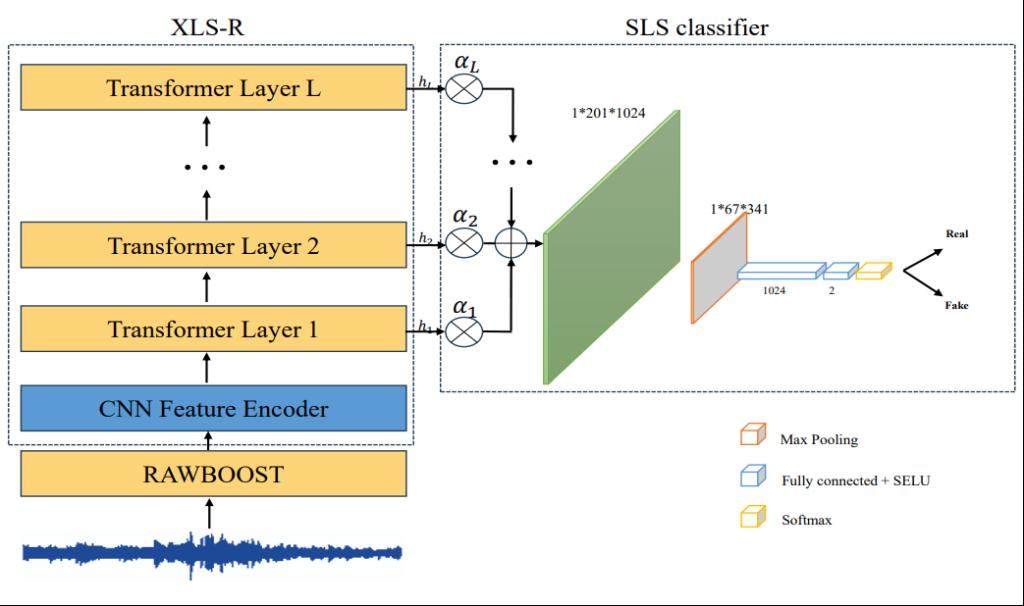
图1 提出模型的整体框架
胡涛教授团队长期从事人工智能安全方向的研究工作,这是湖北民族大学作为唯一单位的第一篇CCF A类会议论文,也是湖北民族大学在人工智能安全领域的突破。该成果受到湖北省自然科学基金联合基金(2023AFD061)和湖北民族大学高水平科研成果校内培育项目(PY22011)支持。
(作者:胡涛 编辑:任达华 审核:钱楷)
